We Built AI Agent Backends That Actually Work in Production – Here’s How
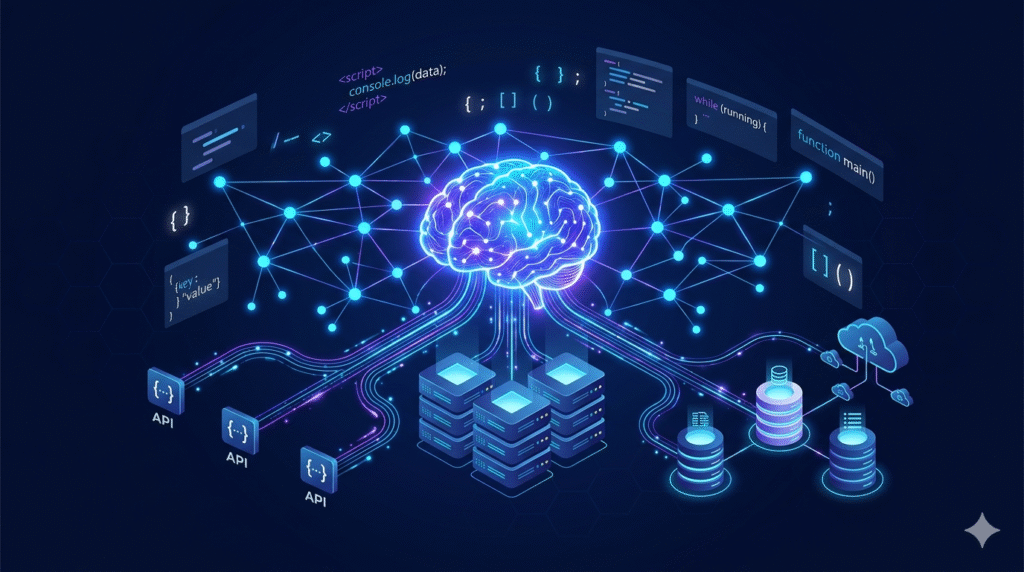
Building AI-powered products is exciting, but turning that excitement into stable, scalable, production-ready software is a completely different challenge. Our engineering team has had the opportunity to design and ship intelligent agent platforms from the ground up, and in this post we’re sharing the key technical decisions, hard-won lessons, and architectural patterns that make it work.
The Challenge: Building AI Agents That Actually Scale
Most AI demos look impressive. Most AI products in production do not work the way the demo suggested. The core challenge every AI team faces is the same: how do you take a language model that produces brilliant but unpredictable output and wrap it in a system that is reliable, fast, and maintainable?
Our answer is to treat the LLM as one component in a well-structured backend, not the entire product. Here’s how we approach each layer.
1. API Design: Scalable RESTful Endpoints for AI Features
The foundation of everything we build is a clean, scalable REST API. We design endpoints to be stateless and composable, which means each AI feature whether it’s generating a response, searching the web, or retrieving memory is exposed as an independent, testable endpoint.
Our key decisions:
- We use async request handling throughout to prevent blocking on LLM calls, which can take 3–10 seconds
- We apply rate limiting at the API layer to protect against model cost overruns
- We version all endpoints from day one (
/api/v1/...) so we can iterate without breaking clients
This discipline of clean API design pays off enormously when integrating multiple AI providers something our team does on every major project.
2. Multi-Model AI Integration: OpenAI and Gemini Side by Side
One of the most technically interesting aspects of our AI work is integrating both OpenAI and Google Gemini APIs into the same backend. Each model has different strengths, pricing, and latency profiles, so having both available gives us and our clients real flexibility.
Our approach:
- We build a unified
LLMProviderabstraction layer so the calling code doesn’t care whether it’s talking to GPT-4o or Gemini 1.5 Pro - We implement automatic fallback, if one provider returns an error or times out, the system retries on the other
- We enable real-time web search for both models, giving agents the ability to answer questions with up-to-date information rather than being limited to training data
This architecture is one of the strongest decisions we make on every AI engagement, model prices and capabilities change fast, and a provider-agnostic layer gives clients the freedom to swap models without touching business logic.
3. Vector Databases: Giving Agents Long-Term Memory
Stateless LLMs forget everything between conversations. For intelligent agents to feel genuinely useful, they need memory. We solve this with a vector database, storing embeddings of past interactions, documents, and knowledge so the agent can retrieve relevant context at inference time.
The pattern we use:
- On every meaningful interaction, we generate an embedding and store it with metadata
- At query time, we perform a similarity search to retrieve the top-K most relevant pieces of context
- We inject that context into the system prompt before calling the model
This retrieval-augmented generation (RAG) approach dramatically improves response quality, especially for users who return to the platform after days or weeks away. In our experience, RAG beats fine-tuning for the vast majority of real-world use cases, it’s faster, cheaper, and far easier to maintain.
4. GDPR-Compliant File Upload and Sensitivity Handling
Operating in the EU means GDPR is non-negotiable, and we treat privacy as an engineering discipline, not a legal checkbox. One of the features we’re most proud of is our file upload pipeline that automatically assesses the sensitivity of uploaded content before storing or processing it.
Our system:
- Scans uploaded files for categories of sensitive data, personal identifiers, financial information, health data — using a combination of pattern matching and lightweight classification models
- Flags high-sensitivity files for additional consent checks before passing them to the AI pipeline
- Ensures all personal data is processed in accordance with data minimisation principles, only what is needed is stored, and only for as long as needed
This approach isn’t just about compliance. For enterprise clients, knowing that their data is handled responsibly is a genuine competitive differentiator, and it’s something we bake into every solution we deliver.
5. System Architecture and Database Design
Underneath all the AI features is a traditional relational database doing what relational databases do best: storing structured data reliably. We design schemas carefully to separate concerns:
- User and session data in normalised relational tables
- AI conversation history in a time-series friendly structure
- Embeddings and vector data in a dedicated vector store, separate from the relational database
This hybrid approach relational + vector is increasingly the standard pattern for AI-native applications, and it’s the architecture we recommend and implement for clients building in this space.
Key Takeaways
After building AI-powered backends across multiple projects and industries, here are the lessons we’d pass on to any team starting this journey:
- Treat the LLM as a service, not the system. Wrap it behind a clean interface. Your business logic should not depend directly on a specific model provider.
- Async everything. AI API calls are slow. Design for it from the start.
- RAG beats fine-tuning for most use cases. Before spending weeks fine-tuning a model, try giving it better context first, it’s faster, cheaper, and more maintainable.
- GDPR is an engineering challenge, not just a legal one. Build privacy into the data pipeline from day one, not on top of it later.
- Provider abstraction is worth the extra effort. The AI landscape changes monthly. Don’t let your infrastructure change with it.
At InitHere, this is how we work. Whether you’re building an AI agent, a SaaS platform, or a custom backend, our team brings production-grade engineering to every engagement. Get in touch to talk about your project the first consultation is free.